


From personalizing your Netflix recommendations to powering self-driving cars, machine learning is revolutionizing everything from entertainment to automation. But what exactly is machine learning? How does it work, and what are its classifications? This blog will introduce you to the fundamentals of machine learning and explore its different types.
If you are new to the machine learning world and want to learn these skills from the basics to advance then you should check out our course Introduction to Machine Learning in which we have all the concepts you need to learn, mentored by industry experts.
What is Machine Learning?
Machine Learning is a subset of Artificial Intelligence (AI) that enables computers to learn from data without being explicitly programmed. It empowers algorithms to analyze data, uncover hidden patterns, and make accurate predictions on new, unseen data, driving smarter decision-making in everything from business to AI applications.
Classification in Machine Learning?
Imagine teaching a computer to distinguish between spam and important emails, or recognizing your friend's face in a crowd. That's the magic of classification in machine learning! Classification is a powerful technique for training machines to categorize data into specific labels or classes. From predicting customer behavior to diagnosing diseases, classification algorithms are at the heart of countless innovations.
Understanding theory is just the start. Try building real models with these hands-on Machine Learning projects to strengthen your skills.
Here are the key classifications of Machine Learning:
Logistic Regression
When it comes to binary classification problems in machine learning, Logistic Regression stands out as a crucial technique. Despite its name, logistic regression isn’t about regression at all—it's a sophisticated method for predicting binary outcomes.
What is Logistic Regression?
Logistic Regression is used to estimate the probability that a given input belongs to a specific category or class. It’s perfect for scenarios where you need to classify data into two distinct groups, such as predicting whether an email is spam or not, or whether a customer will make a purchase.
Why Use Logistic Regression?
- Simplicity and Efficiency: Logistic regression is straightforward to implement and interpret, making it a popular choice for binary classification tasks.
- Probability Estimates: Unlike other classifiers, logistic regression provides a probability score for class membership, offering more nuanced insights.
- Performance with Large Datasets: It performs well even with large datasets, making it ideal for practical applications in various industries.
How Does Logistic Regression Work?
The logistic regression model uses a logistic function (also known as the sigmoid function) to transform its output into a probability score. This score represents the likelihood that a given input belongs to a particular class.
Example: Email Spam Detection
Imagine you want to classify emails as either "Spam" or "Not Spam." Logistic regression can analyse features like email content, sender address, and subject lines to estimate the probability that an email belongs to the "Spam" category.
Logistic Regression in Action
Here’s a visual representation of how logistic regression works:
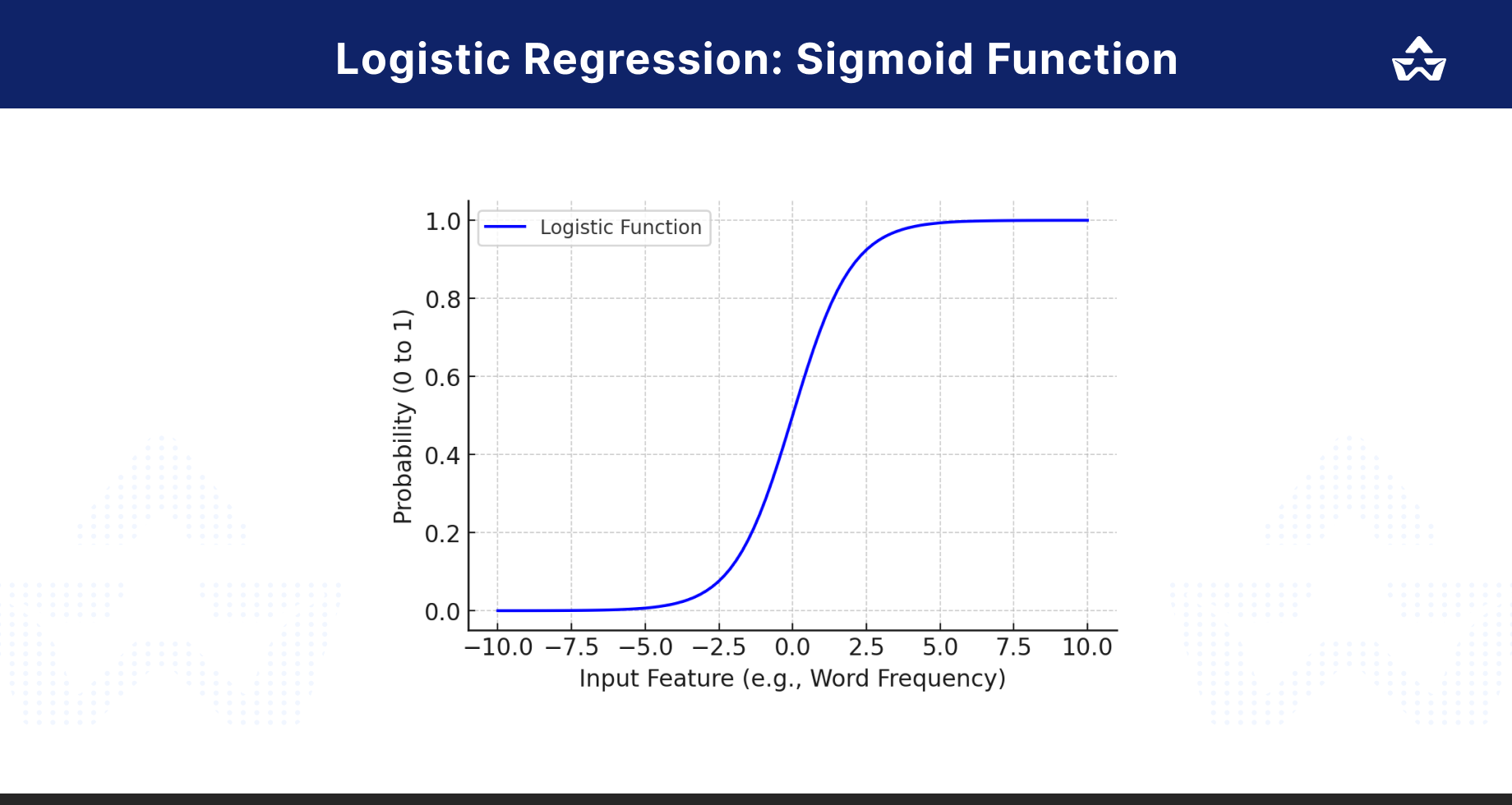
In the chart:
- The x-axis represents different input features (e.g., frequency of specific words).
- The y-axis shows the probability score from 0 to 1.
- The curve illustrates the logistic function, which helps in making binary decisions.
Benefits of Logistic Regression
- Interpretable Results: Provides clear probabilities and straightforward interpretations.
- Robust to Noise: Handles noisy data well and avoids overfitting.
- Versatile: Useful in various domains like healthcare, finance, and marketing.
Super Vector Machine
When it comes to machine learning and classification, Support Vector Machines (SVMs) are a powerful tool that excels in finding the optimal boundary to separate different classes. If you're diving into the world of classification algorithms, understanding SVMs is crucial.
What Are Support Vector Machines (SVM)?
Support Vector Machines (SVM) are a type of supervised learning algorithm used for binary classification tasks. The primary objective of SVM is to identify the best possible boundary (or hyperplane) that separates data points of different classes in a feature space. This boundary helps classify new data points into the correct categories.
Why Choose SVM?
- Effective in High-Dimensional Spaces: SVMs are particularly powerful when dealing with complex datasets with many features.
- Robust to Overfitting: SVMs work well even when the number of dimensions exceeds the number of samples.
Versatility: SVMs can be adapted to solve non-linear classification problems using kernel tricks.
How SVM Work?
SVM finds the optimal hyperplane by maximizinganalyze the margin between data points of different classes. The margin is the distance between the hyperplane and the nearest data points from either class, known as support vectors.
Example: Classifying Emails
Imagine you want to classify emails into "Spam" and "Not Spam." An SVM model can analyze features such as the frequency of certain words or the presence of specific phrases. The SVM algorithm will determine the hyperplane that best separates the spam from the non-spam emails, allowing for accurate classification of new messages.
SVM in Action
Here’s a visual representation of how SVMs work:
- The X-Axis represents different features (e.g., frequency of keywords).
- The Y-Axis represents the classification outcome (e.g., Spam or Not Spam).
- The Hyperplane is the optimal boundary separating different classes.
- Support Vectors are the closest data points to the hyperplane, crucial for defining the margin.
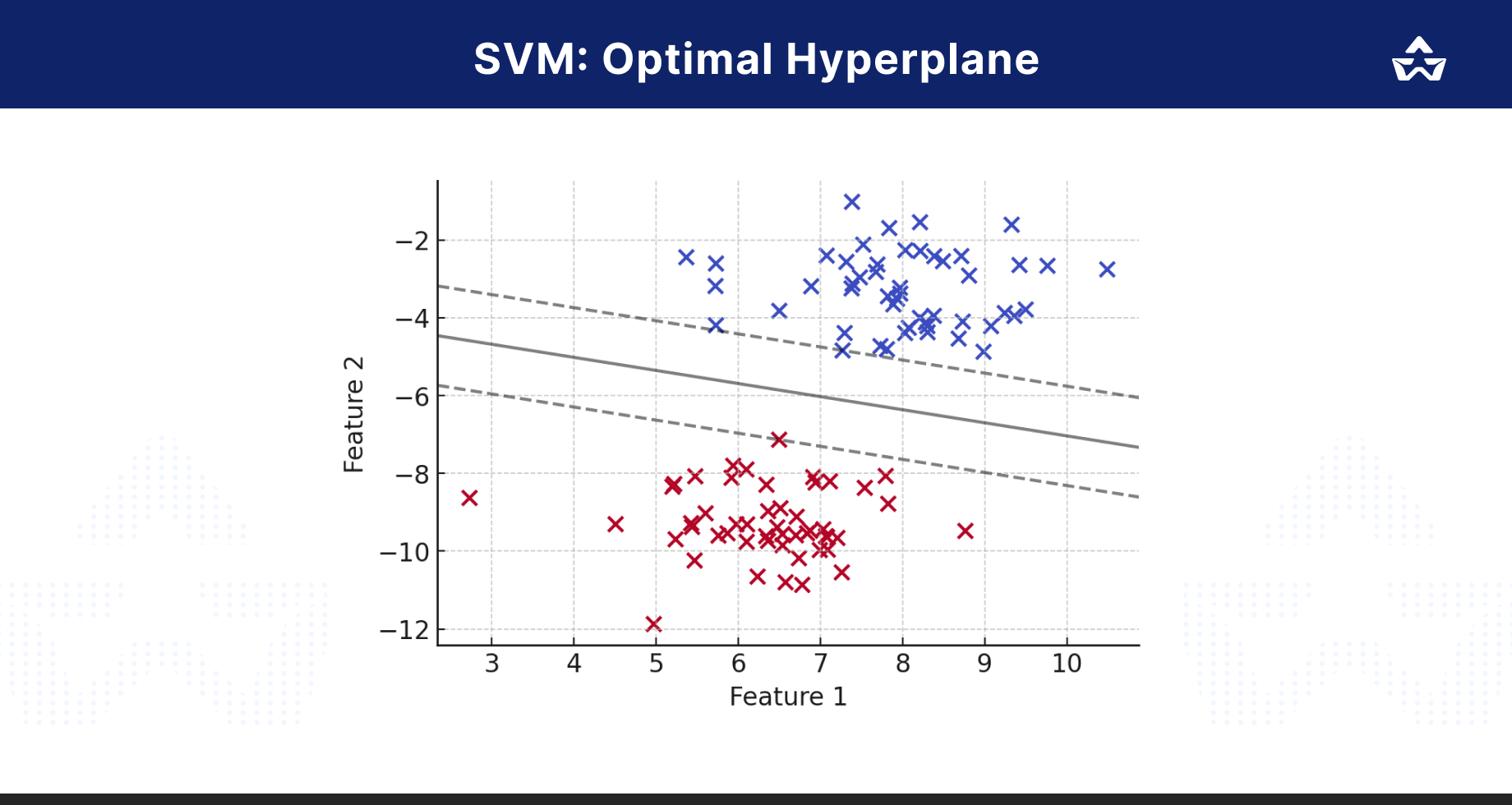
Benefits of Using SVM
- Precision: Provides accurate and reliable classification by focusing on the support vectors.
- Flexibility: Can handle both linear and non-linear classification problems with the right kernel.
- Scalability: Performs well on both small and large datasets.
Naive Bayes
What is Naive Bayes?
It is a probabilistic classifier based on Bayes' theorem with an assumption of independence between features. Despite its simplicity, it delivers impressive results in various applications, particularly in text classification.
Why Naive Bayes?
- Efficiency: Naive Bayes is computationally efficient and works well with large datasets.
- Simplicity: Its straightforward approach makes it easy to implement and interpret.
- Text Classification: Especially effective for classifying text documents, such as spam detection or sentiment analysis.
How Naive Bayes Works?
Naive Bayes calculates the probability of each class given the features of an input. It assumes that each feature is independent of the others, simplifying the computation and speeding up the classification process. The class with the highest probability is chosen as the final prediction.
Example: Spam Detection in Emails
Consider a spam detection system for emails. Naive Bayes can analyse features like the occurrence of certain words or phrases. For example, if an email contains the words "win," "free," and "money," Naive Bayes calculates the probability that the email is spam based on these features.
Naive Bayes in Action
Here’s a visual representation of how Naive Bayes works:
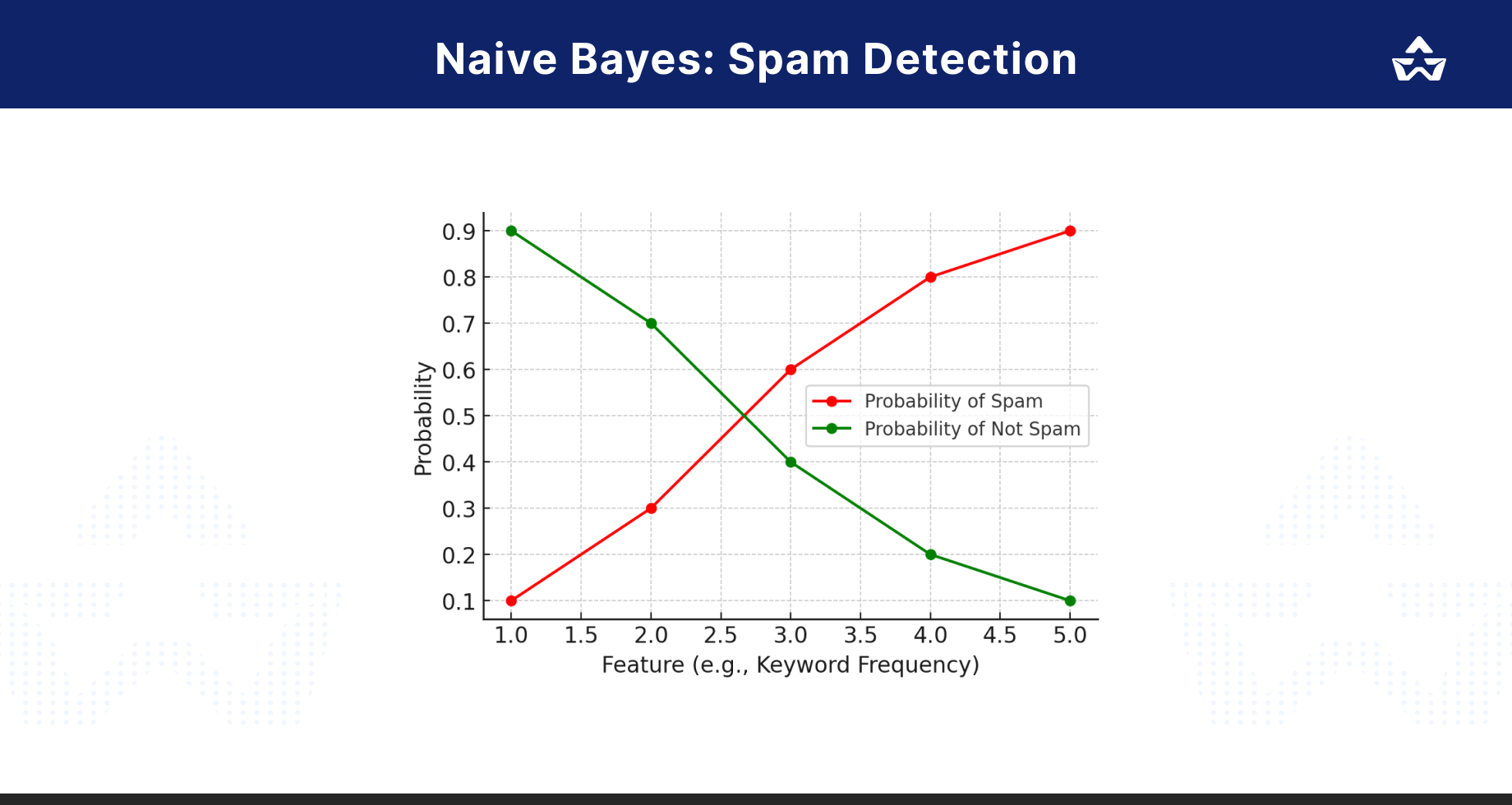
- The X-Axis represents different features (e.g., keywords in an email).
- The Y-Axis represents the probability of the email being spam or not.
- The Probabilities are computed based on the frequency of features in each class.
Benefits of Naive Bayes
- Scalability: Handles large volumes of data with ease.
- Robustness: Effective even with noisy data or missing values.
- Performance: Delivers fast and accurate results for text classification tasks.
K-Nearest Neighbors (KNN)
In the realm of machine learning, K-Nearest Neighbors (KNN) is a widely used algorithm known for its simplicity and effectiveness. If you’re delving into data classification, understanding how KNN works can be incredibly beneficial.
What is K-Nearest Neighbors (KNN)?
K-Nearest Neighbors (KNN) is a classification algorithm that assigns a class label to a data point based on the class labels of its nearest neighbours in the feature space. The idea is straightforward: the more similar or closer the neighbours are to a data point, the more influence they have on the classification decision.
Why Use KNN?
- Simplicity: KNN is easy to understand and implement, making it an excellent choice for beginners.
- Versatility: It works well for both classification and regression tasks.
- Non-parametric: KNN doesn’t assume any underlying distribution of the data, making it flexible.
How KNN Works
KNN operates by calculating the distance between a test point and all points in the training dataset. The algorithm then selects the ‘k’ closest training examples and determines the most common class among them. The class with the majority vote is assigned to the test point.
Example: Classifying Handwritten Digits
Imagine you want to classify handwritten digits (0-9). KNN can be used to compare a new digit against a dataset of labeled digit images. By finding the 'k' nearest neighbors (e.g., 5 nearest images), KNN predicts the digit based on the most frequent class among these neighbors.
KNN in Action
Here’s a visual representation of how KNN works:
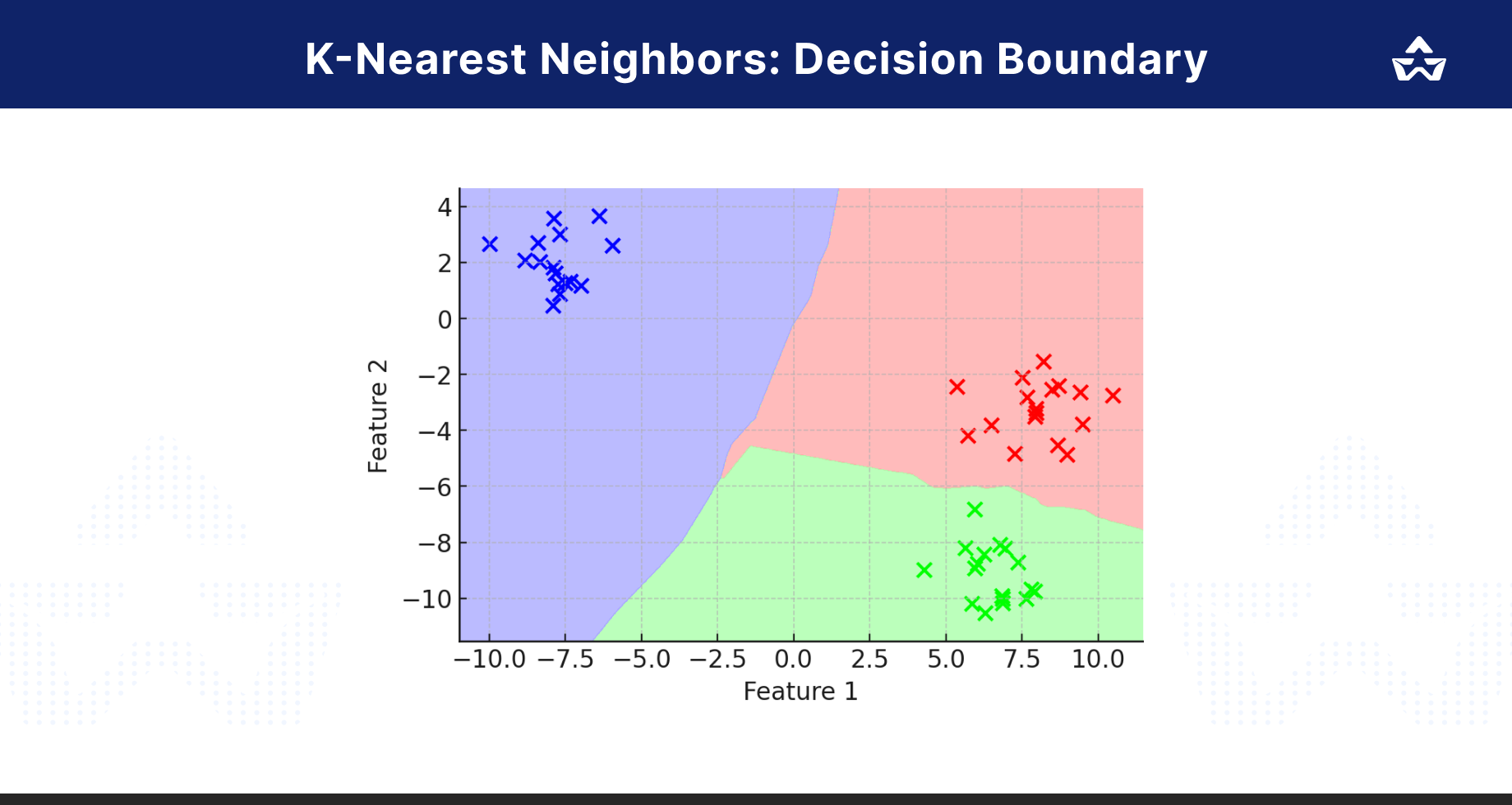
- The X-axis and Y-axis represent feature dimensions (e.g., pixel values in an image).
- Data Points are plotted according to their feature values.
- The Decision Boundary shows how the algorithm classifies the space based on the nearest neighbours.
Benefits of KNN
- Ease of Use: Simple to understand and implement.
- Adaptability: Can handle various types of data without needing a specific model.
- No Training Phase: The algorithm doesn’t require a training phase, which can be advantageous in some scenarios.
Drawbacks of KNN
- Computationally Expensive: As the dataset grows, calculating distances for each query point can become slow.
- Sensitive to Noise: KNN can be affected by noisy data or irrelevant features.
Conclusion
Machine learning is revolutionizing industries from entertainment to autonomous driving. At its core, classification is a key driver, turning raw data into meaningful insights. Whether it's predicting spam emails, diagnosing diseases, or enhancing recommendations, classification algorithms like Logistic Regression, Support Vector Machines (SVM), Naive Bayes, and K-Nearest Neighbors (KNN) are pivotal.
Ready to dive deeper? Check out our Introduction to Machine Learning course, designed to take you from beginner to expert. Learn from industry leaders and master the techniques that drive today’s innovations. Start your journey and transform data into decisions!







