
.jpg%3Falt%3Dmedia%26token%3D4f4654ba-0190-43ef-9987-4d2e54b6c05b&w=128&q=75)

Agenda:
- Virtual memory
- Demand paging
- Page faults in demand paging
- Disadvantages (thrashing)
- Demand paging
- Page Replacement
- FIFO
- Optimal
- LRU
- Disk Scheduling
- Disk Management
Virtual Memory
Virtual memory is a powerful memory management technique that enables a system to run applications and processes that require more memory than is physically available in the computer. It creates an illusion for the user and applications that they are working with a large, contiguous block of memory, even though the actual physical memory (RAM) may be much smaller. Virtual memory achieves this by utilizing both the main memory (RAM) and secondary storage (like a hard drive or SSD) to create an extended "virtual" space larger than the available RAM.
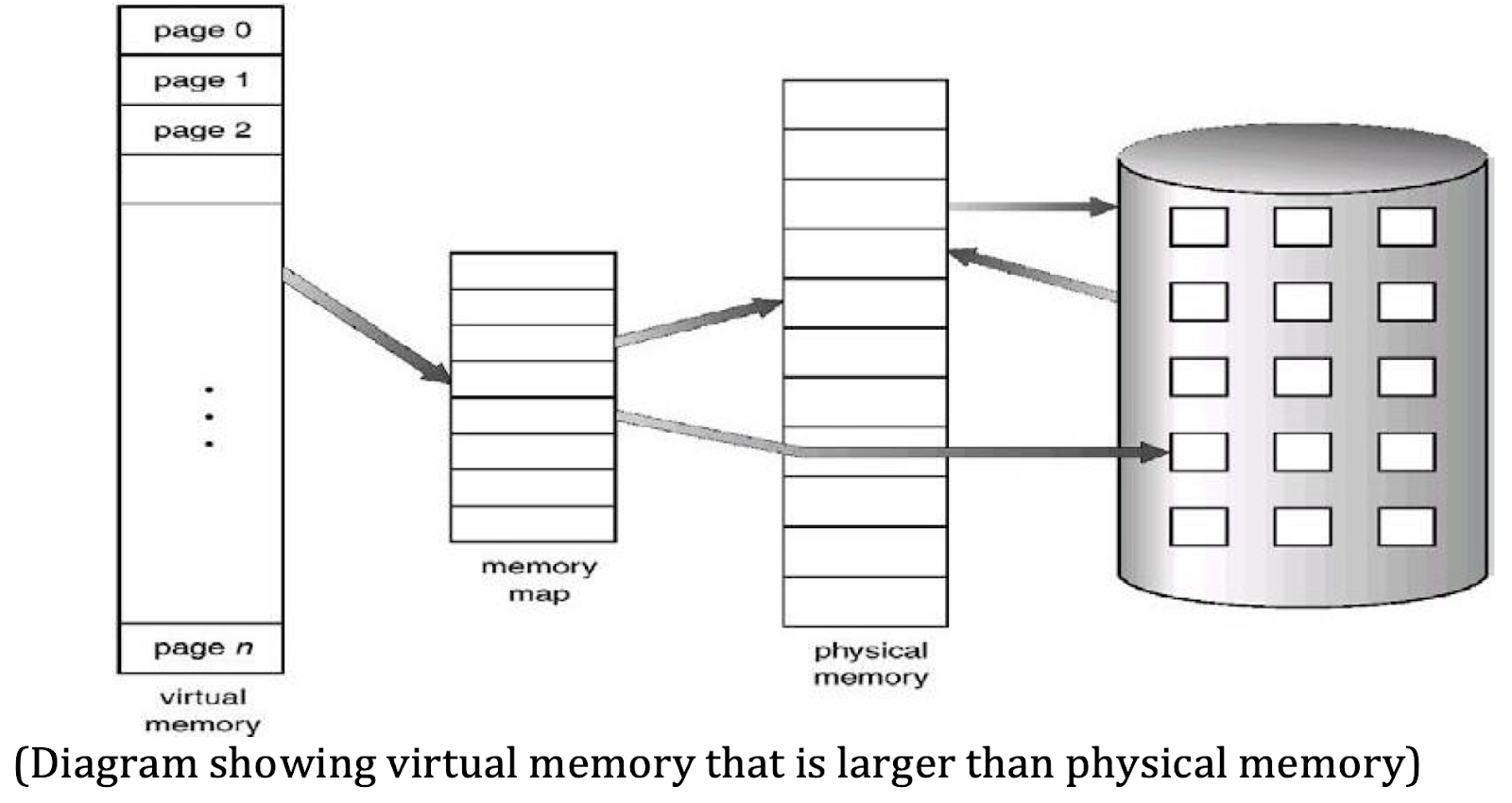
How Virtual Memory Works
Virtual memory separates logical memory (the memory the program sees and works with) from physical memory (the actual RAM in the computer). This separation enables the system to present a large virtual address space to each process, even if the physical memory is limited. Here's how it achieves this:
- Logical vs. Physical Address Space:
- Logical address space refers to the addresses generated by a program. These are virtual addresses and form what appears to the program as a large, contiguous memory block.
- Physical address space is the actual memory location in RAM where data is stored.
- Virtual memory maps logical addresses to physical addresses, allowing the logical address space to be much larger than the actual physical memory.
- Swap Space:
- A dedicated portion of the secondary storage, called swap space, is reserved to store parts of data or program code that do not currently fit in the physical memory. When the system runs low on physical memory, it moves less frequently used portions of a program from RAM to swap space on the hard drive, freeing up RAM for other processes. This technique extends the available memory without needing more physical RAM.
- Illusion of Large, Contiguous Memory:
- Virtual memory allows the operating system (OS) to provide each process with its own large, isolated address space. This means that even if a program is larger than the physical memory, it can still be executed because only the necessary parts of the program are loaded into RAM as needed. The rest resides in swap space and can be brought into RAM on demand.
- Efficiency for Users and System:
- Virtual memory increases system efficiency by loading only the essential parts of each program, which reduces the demand on physical memory and allows the OS to support multiple programs simultaneously. This not only optimizes CPU utilization but also improves overall system throughput by enabling more processes to run concurrently without overwhelming the RAM
Advantages of Virtual Memory
Virtual memory offers several benefits for both users and system developers:
- Support for Larger Programs:
- Programs are no longer limited to the size of the physical memory. Virtual memory allows each program to work within its virtual address space, which can be significantly larger than the actual RAM, enabling the execution of complex applications that might not otherwise fit into physical memory.
- Process Isolation and Security:
- Each process has its own virtual memory space, preventing it from accessing memory being used by other processes. This provides a layer of security and stability, as processes cannot inadvertently interfere with each other's memory.
- Easier Programming:
- Virtual memory abstracts the physical memory limitations, making it easier for programmers to develop software without worrying about the hardware’s memory constraints. They can write programs as though there is a large, contiguous memory space available, and the OS handles the allocation details.
- Enhanced System Throughput and Utilization:
- By loading only the necessary portions of programs, virtual memory allows more processes to fit within the physical memory, thereby enabling multitasking. This results in better CPU utilization and higher throughput.
- Efficient Memory Use:
- Virtual memory enables efficient use of memory by allowing only the needed parts of a program to reside in physical memory. This is particularly useful in scenarios where only certain functions or data structures are needed at specific times.
Implementation of Virtual Memory
Virtual memory can be implemented using different techniques. The two most common methods are:
- Demand Paging: Loads only the required pages of a program into memory on demand, rather than loading the entire program upfront.
- Demand Segmentation: Works similarly but organizes memory into segments based on program structure, such as code, data, and stack segments, and loads them as needed.
These methods reduce the physical memory required at any given time, enabling the system to handle larger applications and a greater number of simultaneous users.
Demand Paging
Demand Paging is a memory management strategy that loads only the required pages of a process into main memory when they are needed, rather than loading the entire process at once. This is often achieved through a mechanism called a "lazy swapper," which waits until a specific page is accessed before swapping it into memory. Demand paging conserves memory resources, reduces load times, and improves system performance, especially for large processes or systems with limited memory.
Concepts in Demand Paging
- Lazy Swapper:
- A lazy swapper avoids loading pages until the exact moment they are accessed, minimizing unnecessary data transfers and memory usage.
- While a swapper typically moves entire processes between main memory and secondary storage, a pager is more granular and only swaps individual pages, focusing on memory efficiency and responsiveness.
- Page Transfer:
- When a process is about to be executed, the pager estimates which pages will be needed and only loads those into memory. This selective loading reduces both memory usage and load times.
- By avoiding the loading of unused pages, demand paging further minimizes swap time and physical memory demand.

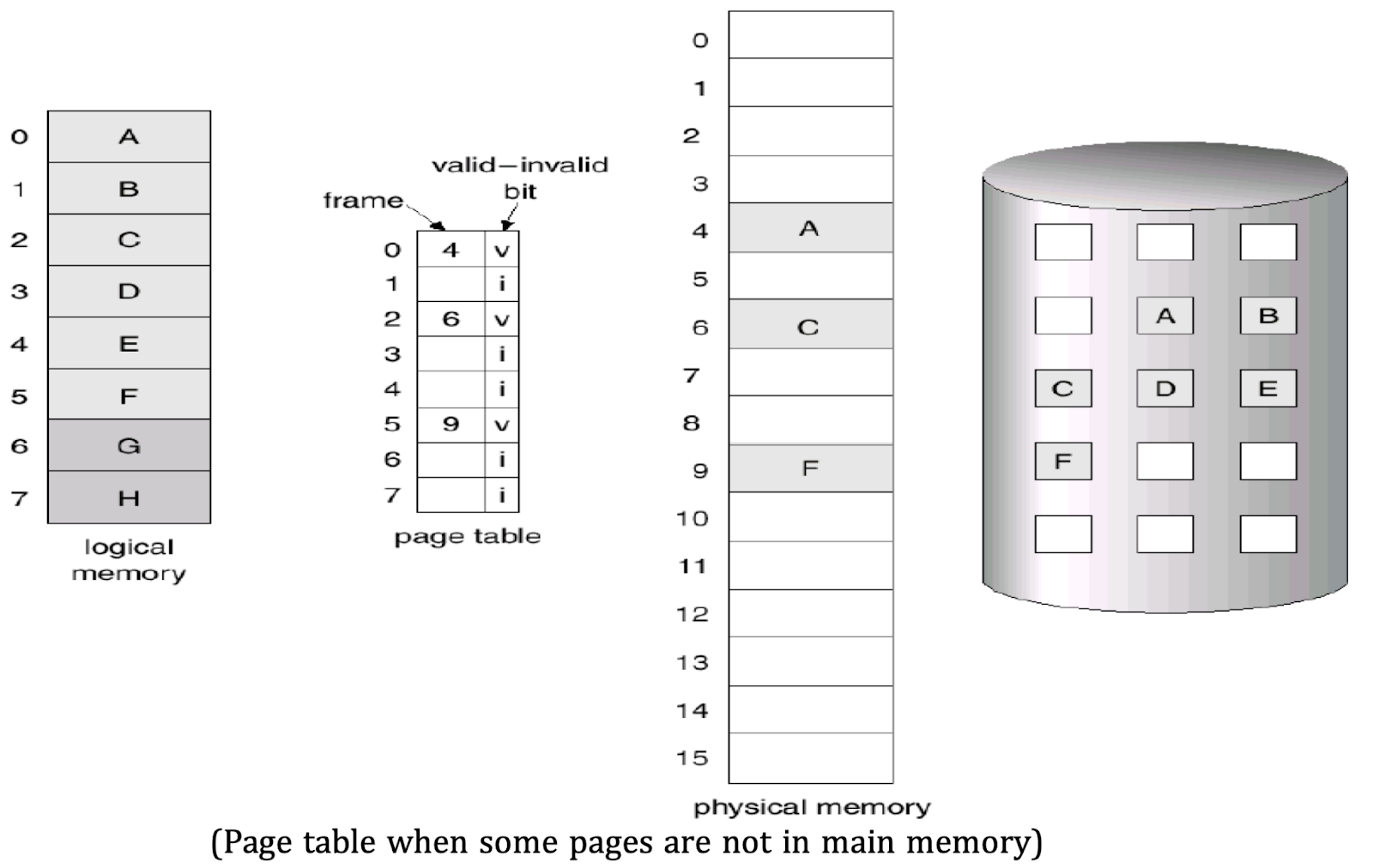
- Page Table:
- Each process has a page table, a data structure that maps virtual memory addresses to physical memory addresses.
- The page table uses a valid-invalid bit scheme:
- Valid bit: indicates that a page is both in memory and within the process’s logical address space.
- Invalid bit: indicates that a page is either not part of the logical address space or is currently on the disk.
- When a page is loaded into memory, its page table entry is updated to "valid." Pages not in memory remain marked as "invalid" or are linked to a disk location where they are stored.
Page Faults in Demand Paging
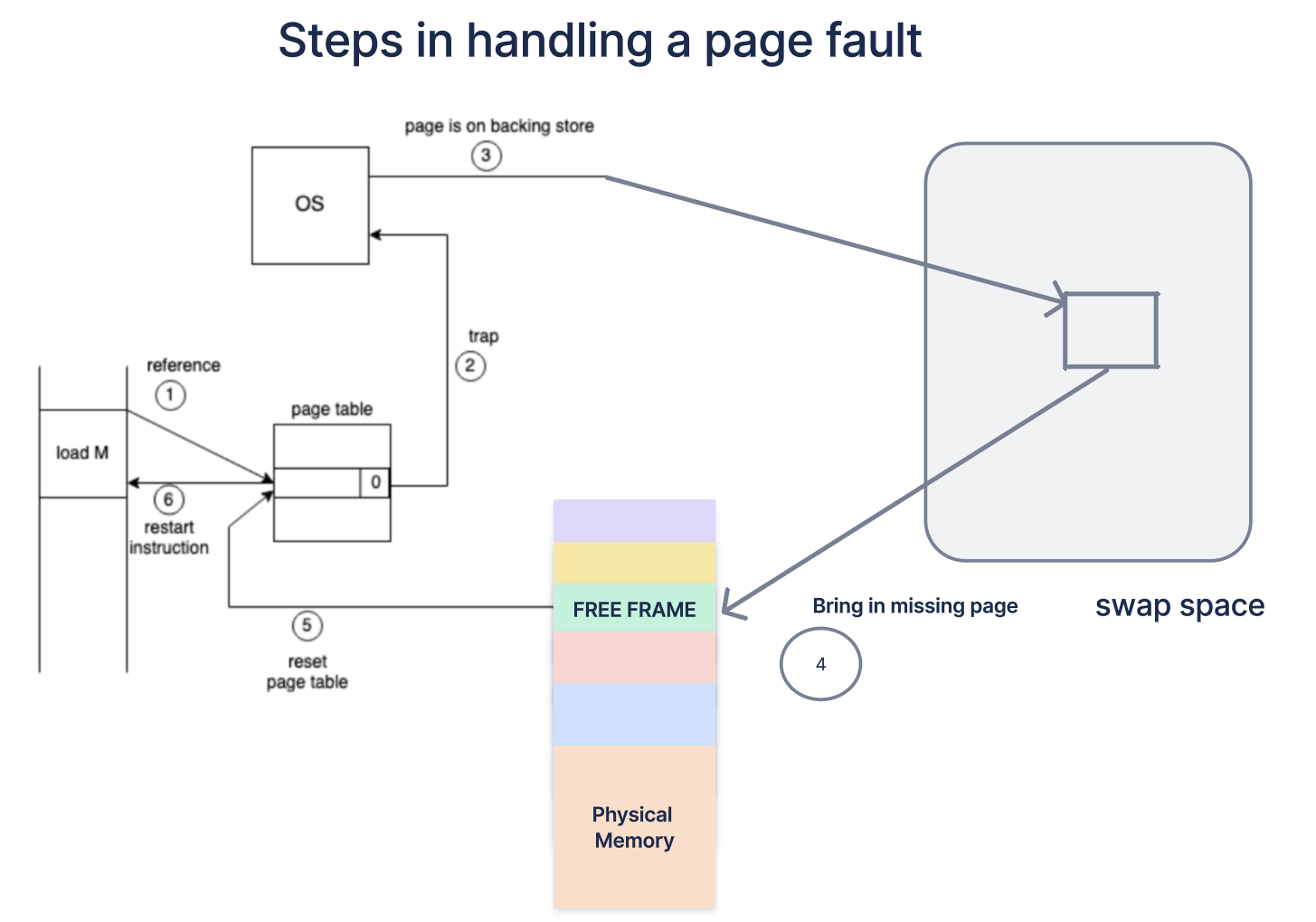
A page fault occurs when a process tries to access a page that is marked invalid in the page table, indicating the page is not currently in main memory. This triggers a series of steps by the operating system to load the required page into memory.
Steps to Handle a Page Fault
- Reference Check:
- The operating system checks the Page Control Block (PCB) or an internal table associated with the process to determine if the page access was valid (within the process’s logical address space).
- If the reference is invalid, it implies an illegal memory access, and the operating system terminates the process.
- Locate Free Frame:
- If the access is valid but the page is not in memory, the operating system finds a free frame from the free-frame list.
- If no free frames are available, a page replacement algorithm selects a page to evict from memory, making room for the new page.
- Read Page from Disk:
- The OS schedules a disk read operation to load the required page from secondary storage (disk) into the allocated free frame.
- Since disk operations are slower than memory access, this step is time-consuming and introduces a delay, impacting system performance.
- Update Page Table:
- After the page is loaded into memory, the page table is updated to reflect its new location. The valid bit is set, marking the page as in memory.
- Restart Interrupted Instruction:
- The CPU restarts the instruction that initially caused the page fault. Now, with the page in memory, the instruction completes successfully as if the page had always been present in main memory.
Performance of Demand Paging
The efficiency of demand paging largely depends on the frequency of page faults and the speed of disk access. The effective access time for a system with demand paging can be calculated using the following formula:
Effective Access Time=(1−p)×Memory Access Time+p×Page Fault Time
where:
- p = probability of a page fault (0 < pp < 1)
- Memory Access Time = time taken to access a page in memory
- Page Fault Time = time taken to service a page fault, including the time to read the page from disk
Page Fault Service Time has three main components:
- Service the Page-Fault Interrupt: Handling the trap and determining if the page reference was valid.
- Disk I/O Operation: Reading the page from disk to memory, which takes much longer than a memory access.
- Process Restart: Restarting the instruction that triggered the page fault.
Advantages of Demand Paging
- Increased Multiprogramming:
- Demand paging allows multiple processes to run concurrently by keeping only the necessary pages of each process in memory. This maximizes the use of available physical memory and increases the degree of multiprogramming.
- Support for Large Applications:
- Applications can run even if their size exceeds the available physical memory, as only the required pages are loaded on demand.
- Memory Efficiency:
- Demand paging conserves memory by only loading required pages, ensuring optimal use of available resources.
Disadvantages of Demand Paging
Page Fault Overhead:
- Each page fault introduces a time delay, as accessing pages on disk is significantly slower than accessing them in memory. Frequent page faults can slow down the system.
Thrashing:
Thrashing is a condition in virtual memory systems where excessive page faults occur, causing the system to spend more time swapping pages in and out of memory than executing the actual processes. This results in a significant drop in system performance and, in severe cases, can cause the system to become nearly unresponsive.
Causes of Thrashing
Thrashing typically occurs when the system is overloaded with too many active processes, each of which requires more pages in memory than are available. This situation leads to frequent page replacements, as the operating system continually swaps pages in and out to accommodate each process's needs.
In a demand-paging system, each process requires a certain number of frames (memory pages) to operate efficiently. If a process doesn’t have enough frames to hold the pages in active use, it will frequently page-fault. Here’s how the thrashing cycle develops:
- Frequent Page Faults: When a process lacks enough frames, each page fault triggers a page replacement. Since the pages in memory are all in active use, the system must evict a page that is likely to be needed soon.
- Repetitive Replacement: The evicted page is quickly needed again, so it must be brought back into memory, causing another page fault.
- Looping in Page Faults: This cycle repeats, leading to the process frequently paging in and out without making meaningful progress.
In essence, thrashing occurs when a process spends more time handling page faults than executing actual instructions. When several processes are thrashing, the system as a whole can fall into an almost unproductive state.

How Thrashing Occurs
- High Page Fault Rate:
- When the required pages of a process are not in memory, page faults occur, and the OS has to bring these pages from secondary storage (e.g., disk). If multiple processes experience frequent page faults, the system quickly becomes overwhelmed with page fault handling.
- Increased Disk I/O:
- Each page fault results in disk I/O operations to fetch the needed pages from disk to RAM. As the page fault rate rises, so does the disk I/O demand, slowing down the overall system performance.
- Less Time Spent on Execution:
- Due to the high page fault rate, the CPU spends most of its time handling page faults and performing disk I/O rather than executing the actual instructions of processes.
- Feedback Loop of More Page Faults:
- As the CPU handles more page faults and the processes continue executing, new page faults are generated. This feedback loop causes thrashing, further reducing the time available for productive execution.
Detection of Thrashing
Operating systems detect thrashing by monitoring the CPU utilization and the page fault rate:
- If the page fault rate is high, but the CPU utilization is low, this may indicate that the system is thrashing.
- In a healthy system, when more processes are added, the CPU utilization should increase. However, if it decreases or plateaus despite additional processes, this suggests that thrashing is occurring, as the system is overwhelmed with managing memory instead of executing instructions.
Thrashing Control and Solutions
There are two main techniques to mitigate or prevent thrashing:
Working Set Model
The working set model is based on the locality principle, which suggests that processes tend to access a particular subset of pages in memory within a given time interval, referred to as the process’s “locality.”
- Current Locality: A process's current locality is the set of pages it actively uses during a specific period. If we allocate enough frames to a process to hold all pages in its current locality, it will experience fewer page faults since all necessary pages are in memory.
- Managing Locality Transitions: When a process moves to a new locality, it may need a different set of pages. If the system can identify and adapt to this shift, it can reduce unnecessary page faults.
- Preventing Thrashing: If a process is allocated enough frames to fit its working set, it will only fault when it transitions to a new locality. If the system provides fewer frames than required, the process will thrash due to the inability to maintain its current locality in memory.
This approach helps prevent thrashing by ensuring that each process has a sufficient number of frames to hold its working set.
Page Fault Frequency (PFF)
The page fault frequency (PFF) technique directly manages the rate of page faults as a way to control thrashing:
- Setting Upper and Lower Bounds: PFF defines acceptable limits for the page fault rate of a process:
- Upper Limit: If the page fault rate exceeds this threshold, it suggests that the process needs more frames to reduce paging.
- Lower Limit: If the page fault rate is below this threshold, it may indicate that the process has more frames than needed, so frames can be reallocated to other processes.
- Dynamic Frame Allocation: By monitoring and adjusting the page fault rate:
- Increasing Frames: When the page fault rate is too high, additional frames are allocated to the process, helping to accommodate its active pages and reduce thrashing.
- Decreasing Frames: When the page fault rate is low, some frames are removed from the process and potentially reassigned to other processes.
- Controlling Page Fault Rate: By maintaining the page fault rate within these bounds, PFF keeps the system balanced, ensuring that each process has adequate resources without over-allocating frames, thus avoiding thrashing.
Impact of Thrashing
- Increased Disk Activity: As page faults become frequent, the system’s reliance on secondary storage increases, which can significantly slow down performance since disk I/O is much slower than RAM access.
- Low CPU Utilization: Thrashing reduces CPU utilization because the processor waits for pages to load rather than executing instructions.
- Reduced System Responsiveness: In severe cases, thrashing can cause system-wide slowdowns, as even basic operations might take longer due to excessive paging.
Pure Demand Paging
Pure Demand Paging is a memory management technique where a process starts executing without any of its pages loaded into main memory. In pure demand paging, pages are only loaded into memory when they are explicitly accessed by the process for the first time, causing a page fault. This lazy-loading approach maximizes memory efficiency by ensuring that only the pages the process actually needs are loaded, conserving memory resources.
- No Preloading:
- Unlike other memory management techniques, pure demand paging does not load any pages into memory at the start of the process. All pages are initially stored in secondary memory (disk), and each page is loaded into main memory only when the process specifically requests it.
- Initial Page Fault:
- As the operating system sets the instruction pointer to the first instruction of a process, which is not yet in memory, the process immediately encounters a page fault.
- This page fault causes the OS to load the required page from secondary storage into main memory. The process can then proceed with execution until it requires another page not in memory, triggering further page faults.
- On-Demand Page Loading:
- Pure demand paging ensures that a page is only loaded when it is needed, or "on-demand." No unnecessary pages are loaded, meaning memory is used very efficiently.
- This can be beneficial for large programs that may use only a small portion of their code or data during execution, avoiding unnecessary memory usage.
- Utilizes Locality of Reference:
- Pure demand paging relies on the concept of locality of reference, where processes tend to access a set of pages repeatedly during specific periods of execution.
- Due to locality, only a small subset of pages is typically required in memory at a time, allowing pure demand paging to achieve reasonable performance despite initially high page fault rates.
Advantages of Pure Demand Paging
- Memory Efficiency: Since only the pages needed are loaded, memory utilization is optimized, conserving resources for other processes.
- Support for Large Processes: Pure demand paging allows large applications to run even on systems with limited physical memory, as only a small subset of pages may be required at any given time.
- Improved Multi-Programming: By loading pages on-demand, pure demand paging frees up memory for more processes to run concurrently.
Disadvantages of Pure Demand Paging
- Initial Page Fault Overhead: Pure demand paging leads to a high number of page faults initially, as the process begins without any pages loaded. This can slow down execution, especially at the start of the process.
- Potential for Thrashing: If the working set of pages required by a process changes frequently, the system may experience excessive page faults, leading to thrashing—a state where the OS spends more time swapping pages in and out than executing processes.
Page Replacement
Page replacement is a critical aspect of virtual memory management in operating systems. It handles situations where a process tries to access a page that is not currently in memory, causing a page fault. The operating system (OS) must then bring the required page from secondary storage (swap-space) into memory. However, memory frames (physical memory) are often fully occupied during high system utilization, requiring the OS to free up a frame by replacing an existing page with the new one. This process is managed by page replacement algorithms.
Importance of Page Replacement
When a page fault occurs, and all frames are busy, the OS has to decide which page to replace to bring the new page into memory. Effective page replacement is crucial because:
- It ensures efficient memory utilization by freeing up space for new pages.
- It helps reduce page fault rates, which keeps CPU utilization high, as the CPU spends less time waiting for pages to load.
- It improves system performance, as better page replacement strategies can lower the frequency of page faults and avoid unnecessary swapping.
Choosing the right page to replace is essential to achieving optimal performance, as it can minimize the number of page faults, which in turn reduces the disk I/O overhead associated with fetching pages from swap-space.
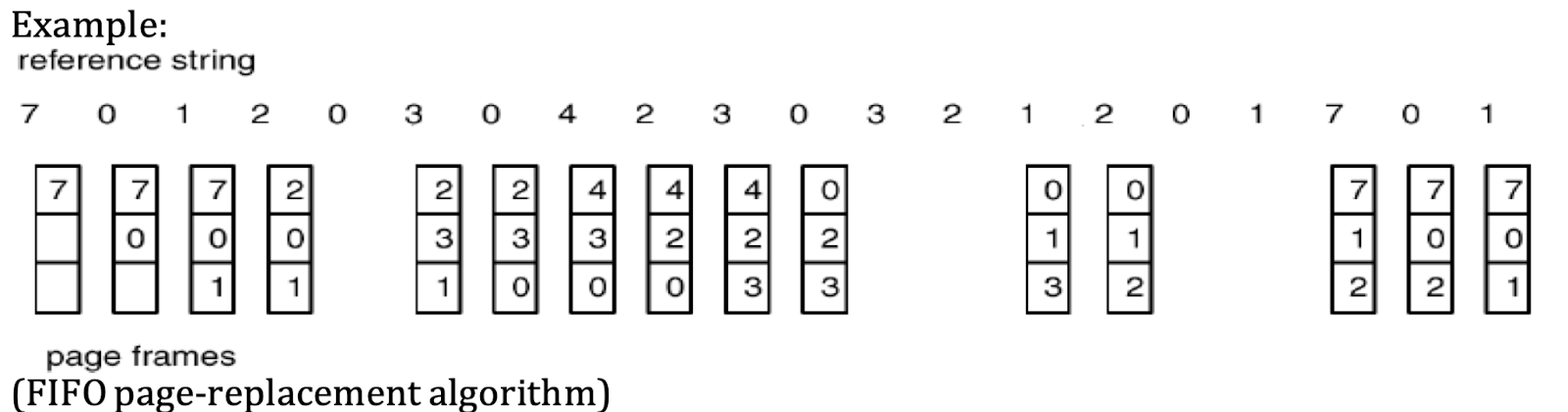
First-In-First-Out (FIFO) Page Replacement Algorithm
One of the simplest page replacement methods is the First-In-First-Out (FIFO) algorithm. In this approach:
- FIFO Queue:
- The OS keeps a FIFO queue of all pages currently in memory, ordered by the time each page was loaded.
- When a new page is required, the page at the head (oldest) of the queue is replaced, and the new page is added to the tail (end) of the queue.
- Mechanism:
- FIFO associates each page with the time it was brought into memory. When a page needs to be replaced, FIFO always selects the oldest page.
- Pages are swapped in and out based on their order in the queue, without regard to how frequently or recently they are accessed.
- Implementation:
- FIFO is simple to implement, as it only needs to maintain the order in which pages were loaded.
- However, its simplicity can sometimes lead to suboptimal performance, particularly if the oldest page happens to be frequently accessed.
Belady’s Anomaly in FIFO
One of the most notable characteristics of the FIFO algorithm is Belady’s anomaly, an unexpected phenomenon in which increasing the number of memory frames can sometimes increase the page fault rate.
- Cause of Belady’s Anomaly:
- In most algorithms like Least Recently Used (LRU) or Optimal Page Replacement, adding more frames typically reduces page faults because more pages can be retained in memory.
- However, FIFO may evict pages in a way that, in certain cases, leads to more page faults despite an increased number of frames.
- Example:
- Consider a scenario where a specific pattern of page requests interacts poorly with the FIFO order. Adding more frames doesn’t necessarily improve the fault rate, as FIFO may still evict pages that will soon be accessed, leading to a higher page fault count.
- Significance:
- Belady’s anomaly illustrates the limitations of FIFO in cases where increasing memory allocation should theoretically improve performance but fails to do so due to the algorithm's design.
- This anomaly is not observed in other algorithms like LRU and Optimal, which are generally more adaptive to the memory access patterns of processes.
Pros and Cons of FIFO Page Replacement
Advantages:
- Simplicity: FIFO is easy to understand and implement since it only requires tracking the order of page loads.
- Low Overhead: It doesn’t require complex tracking of page usage, minimizing the CPU resources needed for implementation.
Disadvantages:
- Performance Issues: Since FIFO does not account for page usage frequency or recency, it may evict critical pages and increase page faults.
- Belady’s Anomaly: FIFO can perform unpredictably in specific cases, where increasing the number of frames actually worsens the page fault rate.
Optimal Page Replacement Algorithm (OPT or MIN)
The Optimal Page Replacement algorithm, often abbreviated as OPT or MIN, was developed as a theoretical solution to minimize page faults in virtual memory management. It emerged as a response to the limitations of simpler algorithms like FIFO, particularly to avoid phenomena such as Belady's anomaly, where increasing the number of memory frames could paradoxically increase page faults. The Optimal Page Replacement algorithm is unique because it guarantees the lowest possible page fault rate for a fixed number of frames, making it theoretically ideal.
Working Mechanism of the Optimal Algorithm
The Optimal Page Replacement algorithm works by predicting future memory accesses to decide which page should be replaced. The strategy is as follows:
- Identify Pages Not Referenced in the Future:
- If a page exists that will never be used again in the future, it is replaced with the incoming page since it’s safe to discard permanently.
- Find the Page Referenced Farthest in the Future:
- If no such page can be identified (which is typically the case in real scenarios), the algorithm selects the page that will not be used for the longest time in the future. This page is then replaced with the incoming page.
- This choice ensures that the page least likely to be needed soon is removed, thus minimizing the chances of a page fault in the immediate future.
Example of Optimal Page Replacement
Consider a sequence of page requests with a fixed number of frames:
- For each new page request, the Optimal algorithm checks the upcoming page requests in the reference string.
- It then replaces the page in memory that will not be needed for the longest time based on this future reference pattern.
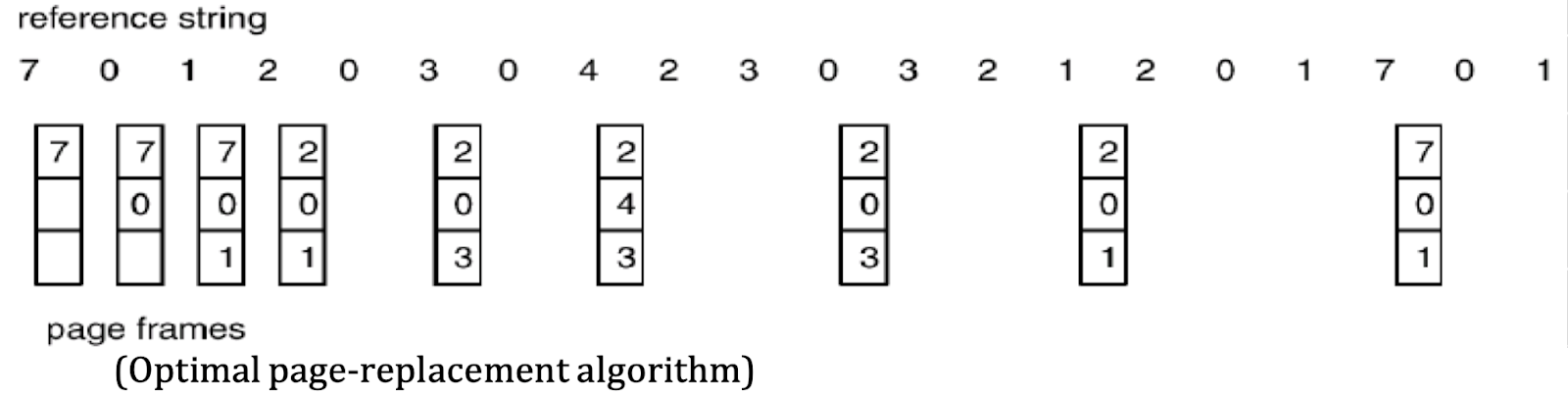
Using this approach, the algorithm ensures that page faults are minimized by only evicting pages that are unlikely to cause future faults.
Benefits
- Lowest Page Fault Rate:
- Optimal page replacement guarantees the minimum page-fault rate among all known algorithms, making it highly efficient in theory.
- No Belady’s Anomaly:
- Unlike FIFO, the Optimal algorithm does not suffer from Belady’s anomaly. Increasing the number of frames will not unexpectedly increase the page fault rate since the algorithm is designed to achieve the lowest possible fault rate regardless of frame count.
- Theoretical Benchmark:
- Optimal page replacement serves as a benchmark against which other page replacement algorithms are evaluated. Since it represents the best possible performance, other algorithms are compared to OPT to measure their efficiency.
Limitations
While Optimal page replacement offers the best performance theoretically, it is not feasible to implement in real operating systems due to the following reasons:
- Requires Future Knowledge:
- To make the optimal replacement choice, the algorithm needs perfect knowledge of future memory accesses (i.e., the reference string). Since it’s impossible for an operating system to predict future accesses accurately, OPT remains a theoretical ideal rather than a practical solution.
- This challenge is similar to that faced in Shortest Job First (SJF) scheduling, where future job lengths must be known to achieve optimal scheduling.
- Limited Practical Application:
- Due to its reliance on future information, OPT is mainly used as a comparison standard rather than a practical algorithm in real systems.
Least-Recently-Used (LRU) Page Replacement Algorithm
The Least-Recently-Used (LRU) page replacement algorithm is a commonly used technique in operating systems for managing memory pages. LRU leverages the recent past as an approximation for the near future, assuming that pages that haven't been used for the longest time are the least likely to be needed soon. LRU aims to minimize page faults by replacing the page that has not been used for the longest period.
How LRU Works
The LRU algorithm keeps track of page access history to identify which page has not been used for the longest time. When a page fault occurs (meaning a page is needed but is not in memory), LRU identifies the least recently used page in memory and replaces it with the new page. This ensures that only those pages that are least likely to be accessed soon are removed, thus helping to maintain optimal memory usage.
Implementation of LRU
Implementing the LRU algorithm requires a mechanism to keep track of when each page was last accessed. There are two common methods for achieving this:
Counters-Based Approach:
- In this method, a logical clock or counter is associated with each page. Whenever a page is accessed, the current value of the clock is stored in a time-of-use field in the page's entry.
- To replace a page, the page with the smallest time-of-use value (indicating it was used the longest time ago) is selected.
- This approach requires searching the page table for the least recently used page and updating the time-of-use field on every memory access, which can be computationally expensive.
Stack-Based Approach:
- A stack of page numbers is maintained where each page accessed is moved to the top. As a result, the top of the stack always represents the most recently used page, while the bottom holds the least recently used page.
- When a page is accessed, it is either moved from its current position to the top (if already in the stack) or added to the top (if it’s a new page).
- The page at the bottom of the stack is evicted upon a page fault.
- A doubly-linked list can be used to efficiently implement this stack to allow easy removal and reordering of entries, though it may still incur a moderate overhead due to continuous updating.
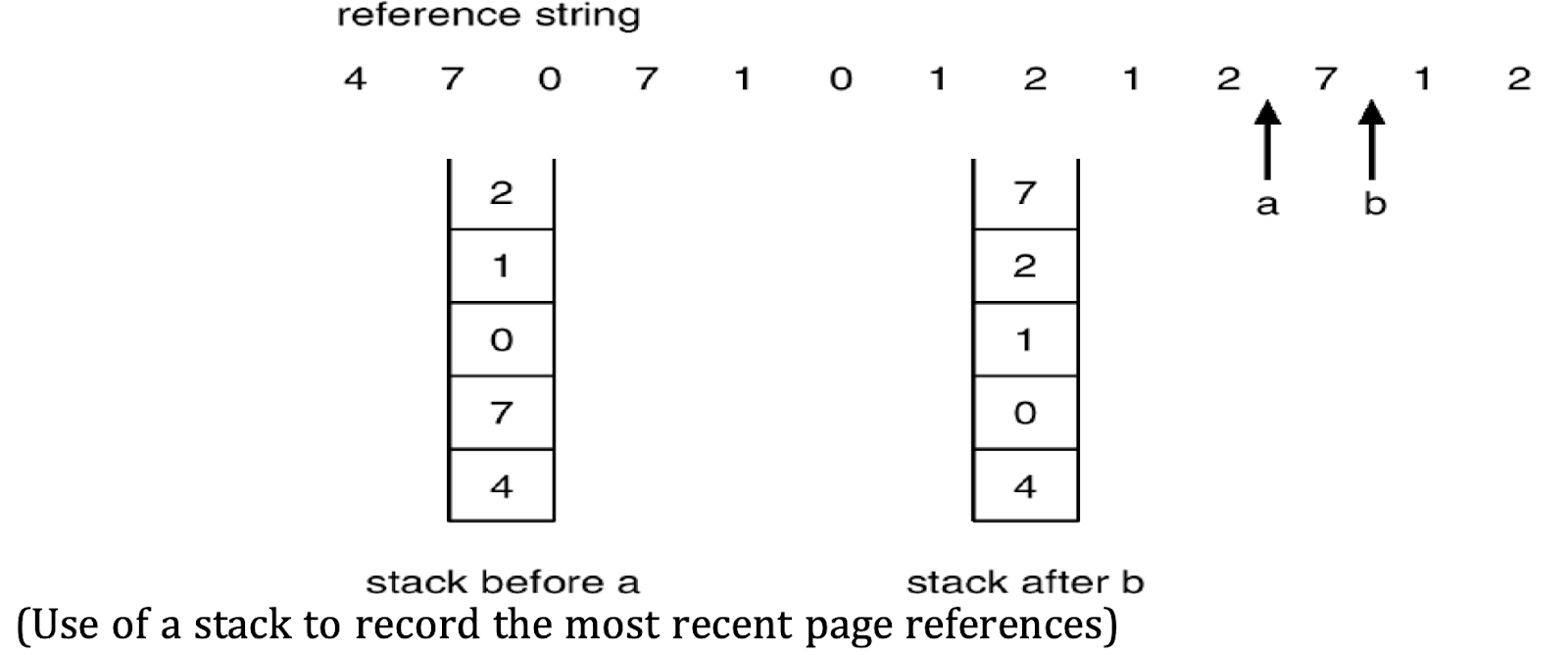
Example of LRU
In the LRU algorithm:
- Suppose there are three frames, and a sequence of page requests: 7, 0, 1, 2, 0, 3, 0, 4.
- Each page request leads to either a page hit (if already in memory) or a page fault (if not).
- After each page fault, the least recently used page among the three frames is replaced with the requested page.

Challenges in Implementing LRU
While LRU is effective in minimizing page faults, its implementation can be complex and may require additional hardware support. Maintaining accurate tracking of page access time or stack management adds overhead, especially with high-frequency memory accesses.
LRU Approximation Algorithms
To simplify LRU implementation, approximation algorithms are often used:
- Additional-Reference-Bits Algorithm:
- This approach associates an 8-bit field with each page in memory. At regular intervals, the system shifts the reference bit of each page into this field.
- The bits create a usage history for each page over the last eight intervals. The page with the lowest value in this field is considered the LRU page and is replaced.
- Second-Chance Algorithm:
- This algorithm combines aspects of FIFO with LRU. When a page needs replacement, the page with the oldest arrival time (FIFO) is checked.
- If the page’s reference bit is set to 0, it is replaced. If the reference bit is 1, it is given a “second chance” (reference bit reset to 0) and the algorithm moves to the next page.
Counting-Based Page Replacement Algorithms
Other methods for page replacement include counting-based algorithms, which track reference counts for each page:
- Least Frequently Used (LFU):
- LFU replaces the page with the smallest access count, assuming that less frequently used pages are less likely to be needed soon.
- Most Frequently Used (MFU):
- In contrast, MFU replaces the page with the largest access count, based on the theory that pages accessed heavily in the past are less likely to be needed in the immediate future.
Counting-based algorithms like LFU and MFU are less common than LRU because they may not always correlate well with actual access patterns, whereas LRU is more effective in practice by focusing on recency of use.
Disk Scheduling
Disk Scheduling is the process of determining the order in which disk I/O requests are processed. Efficient scheduling is essential to minimize latency and improve throughput, ultimately enhancing the overall performance of the system.
Terms in Disk Scheduling
- Seek Time:
- The time required for the disk arm to move to the correct track or cylinder on the disk where the desired data is located.
- Importance: Lower seek time leads to faster access to data.
- Rotational Latency:
- The time it takes for the desired sector of the disk to rotate under the read/write head.
- Reducing rotational latency is crucial for improving data retrieval speed.
- Disk Bandwidth:
- The rate at which data can be read from or written to the disk, usually expressed in bytes per second. It is calculated as the total number of bytes transferred divided by the total time taken from the first request to the completion of the last transfer.
- Higher disk bandwidth indicates better performance and efficiency.
1. FCFS (First-Come, First-Served) Scheduling
- This is the simplest disk scheduling algorithm, processing requests in the order they arrive. It operates on a FIFO (First-In, First-Out) basis.
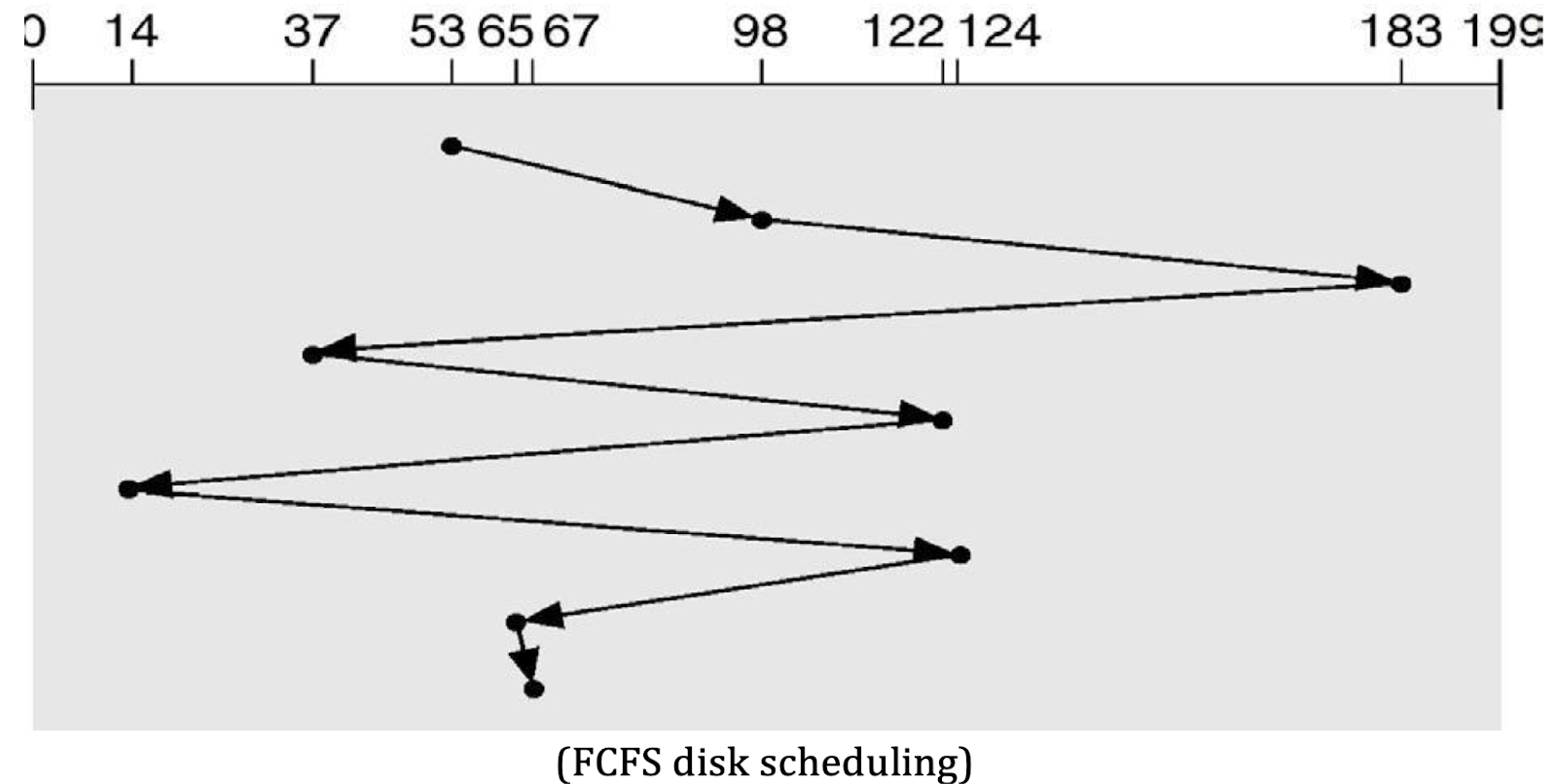
- Example:
- Request Queue: 98, 183, 37, 122, 14, 124, 65, 67
- Starting Head Position: 53
- Servicing Order: The requests are serviced in the order they arrive, which may result in inefficient seek times.
- Pros:
- Easy to implement and understand.
- Cons:
- Can lead to long wait times and high seek times, especially if the head frequently has to travel far between requests.
2. SSTF (Shortest Seek Time First) Scheduling
- This algorithm selects the request with the shortest seek time from the current head position, prioritizing nearby requests.
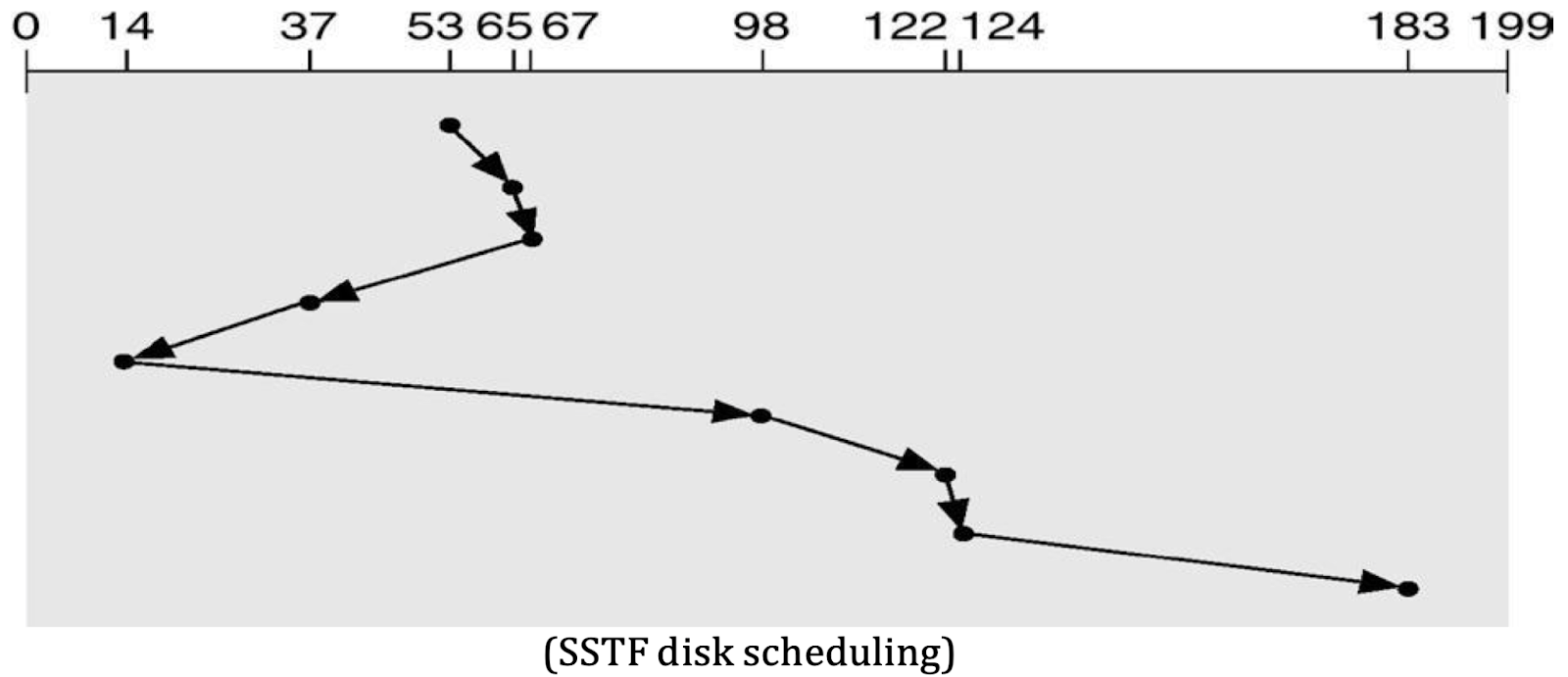
- Example:
- Starting at Cylinder: 53
- The head would service the closest request first, leading to potentially better average seek times.
- Pros:
- Reduces average seek time and improves performance compared to FCFS.
- Cons:
- Can lead to starvation, where some requests may never be serviced if there are constantly closer requests being added.
3. SCAN Scheduling
- The disk arm moves in one direction (e.g., toward the end of the disk), servicing all requests until it reaches the end, then reverses direction and services requests on the return trip.
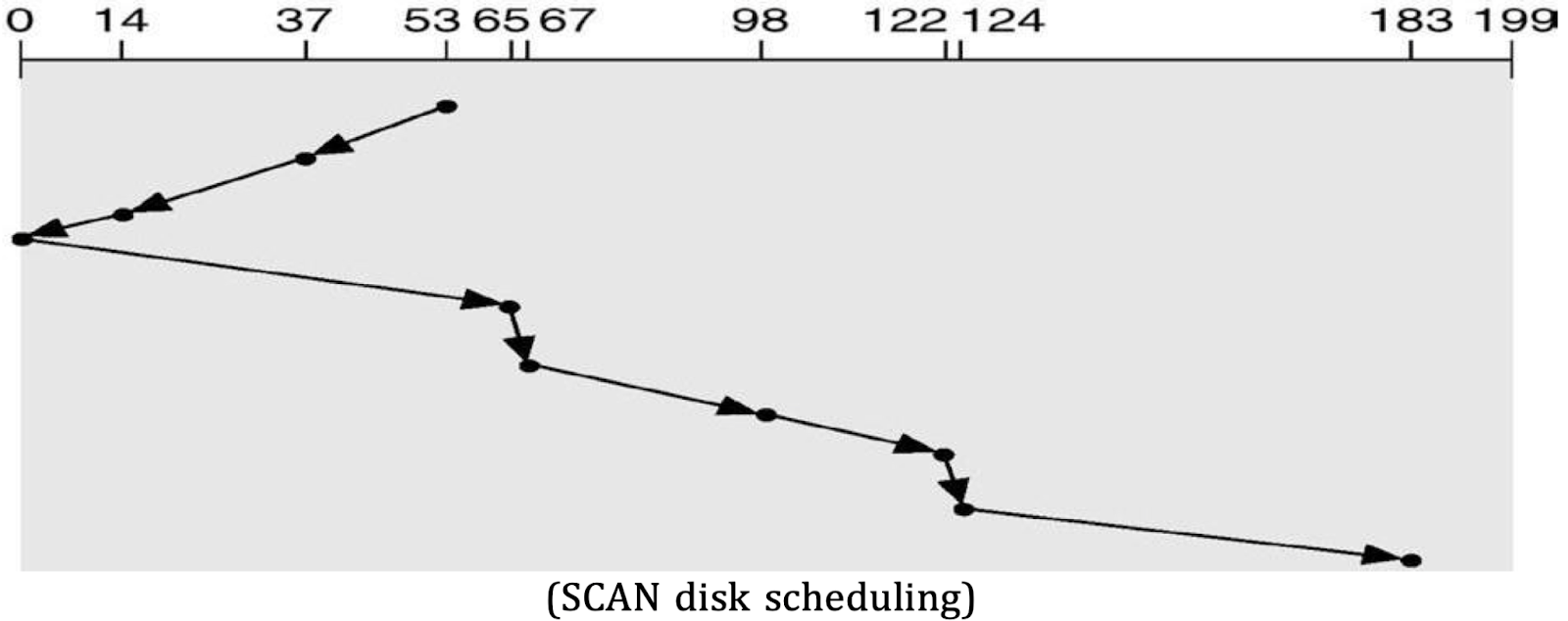
- Example:
- Starting Head Position: 53
- The arm would move right to 98, 122, 124, 183, then reverse and move back servicing the requests in that direction.
- Pros:
- More uniform wait time compared to FCFS.
- Cons:
- Requests at the far ends may experience longer wait times.
4. C-SCAN (Circular SCAN) Scheduling
- Similar to SCAN, but when the head reaches the end of the disk, it jumps back to the beginning without servicing requests on the return trip, effectively treating the disk as a circular queue.
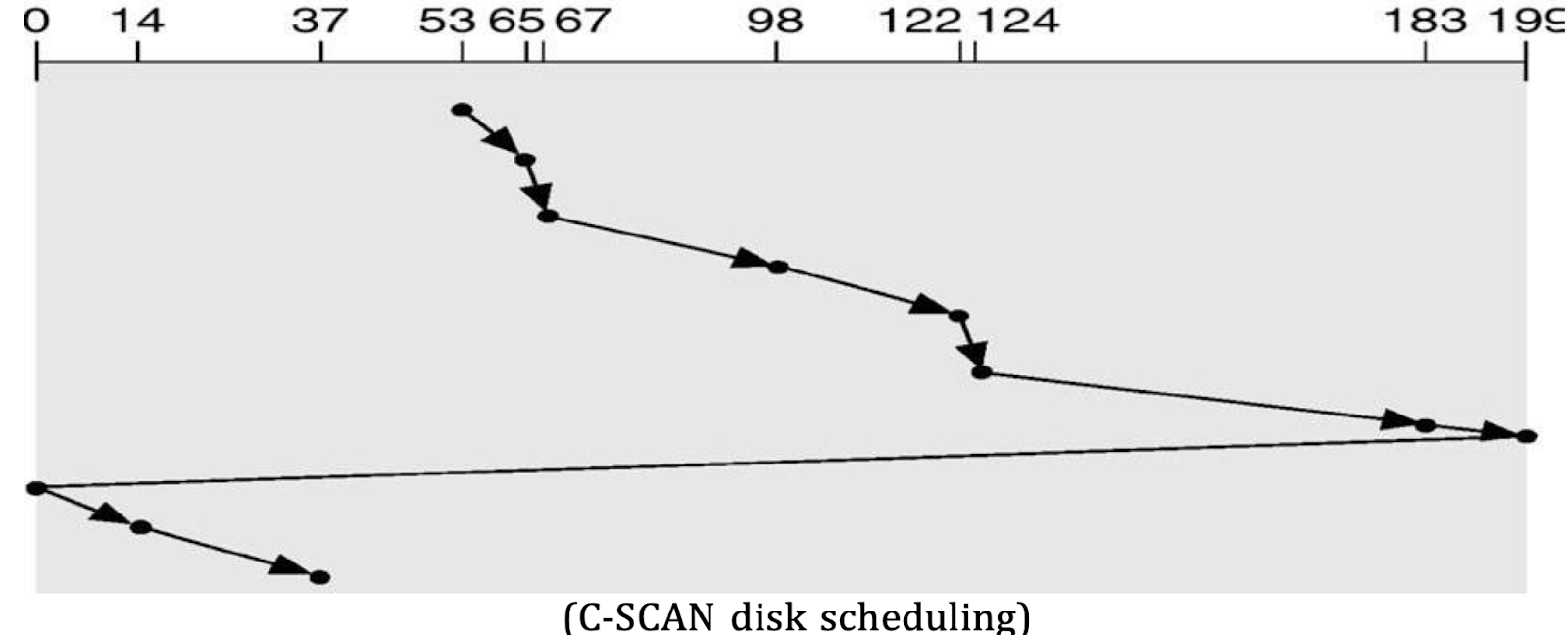
- Example:
- Starting Head Position: 53
- Services requests moving right until it reaches 183, then jumps back to 0 without servicing during the return.
- Pros:
- Provides a more uniform wait time for all requests, preventing the long delays experienced in SCAN.
- Cons:
- Still has delays for requests that are located far from the current head position.
5. LOOK Scheduling
- A practical adaptation of SCAN, where the arm only goes as far as the last request in each direction before reversing direction. It "looks" for requests before moving.
- Pros:
- Reduces unnecessary travel, improving performance and reducing overall wait time.
- Cons:
- Slightly more complex to implement compared to SCAN.
6. C-LOOK Scheduling
- Similar to LOOK, but when the arm reaches the last request, it jumps back to the first request without servicing requests during the return trip.
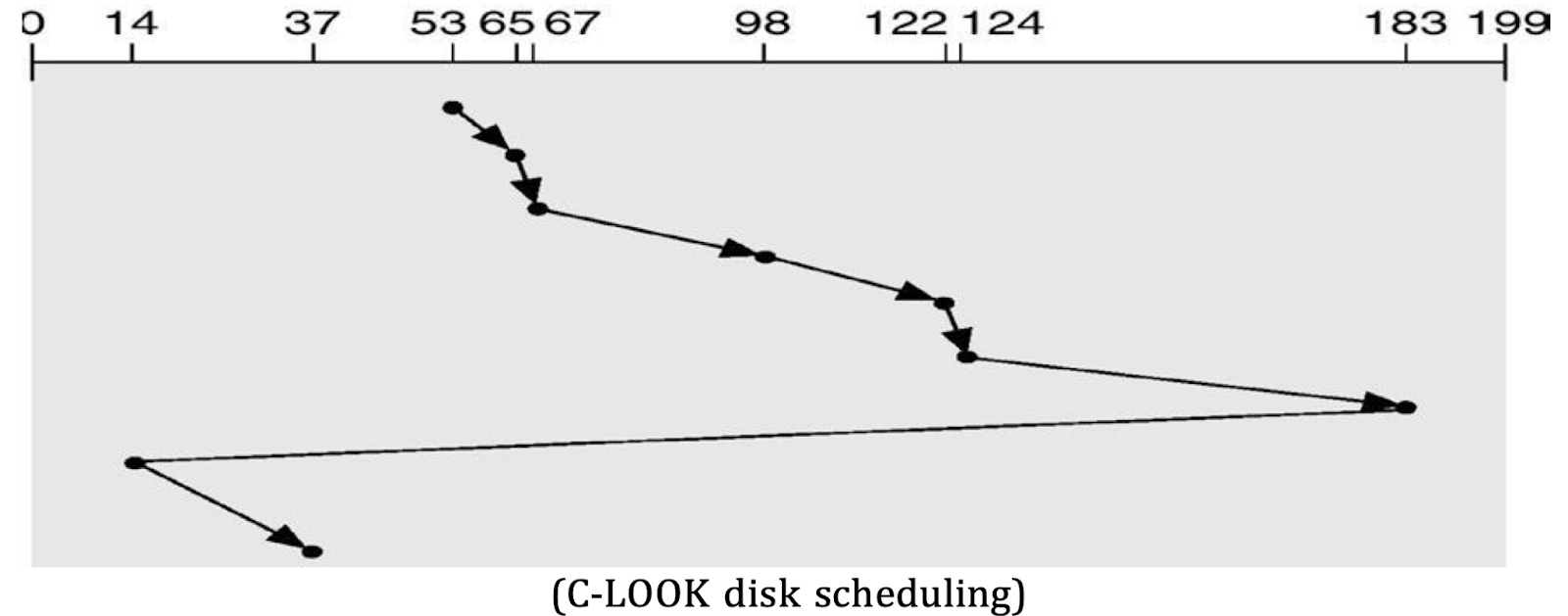
- Example:
- Starting Head Position: 53
- Services requests until it reaches the last request and then jumps back to the first.
- Pros:
- Offers uniform wait time similar to C-SCAN while minimizing unnecessary movement.
- Cons:
- Still requires some overhead to manage the queue of requests.
Selection of a Disk-Scheduling Algorithm
- Performance Considerations: The choice of disk scheduling algorithm depends on the workload characteristics, such as the number and types of requests.
- General Recommendations:
- SSTF is commonly used due to its efficiency in reducing seek time.
- SCAN and C-SCAN are preferred for systems with heavy disk load.
- The disk-scheduling algorithm should be implemented as a separate module in the operating system to facilitate easy replacement with alternative algorithms if needed.
- Either SSTF or LOOK is typically a reasonable default choice for disk scheduling.
Disk Management
Disk management is a fundamental function of the operating system that ensures efficient use and organization of disk resources. It includes various critical tasks to prepare, maintain, and manage disks for data storage.
1. Disk Formatting
Disk formatting is a prerequisite for using a disk for data storage. It involves preparing the disk in a way that allows the operating system to store and retrieve data effectively.
a. Low-Level Formatting
- Low-level formatting is the initial step in preparing a disk. It involves the physical arrangement of data on the disk's surface.
- Process:
- Sector Division: The disk is divided into small, manageable units called sectors. Each sector typically holds a fixed amount of data (commonly 512 bytes).
- Data Structure Creation: Each sector includes a header, a data area, and a trailer:
- Header: Contains essential metadata such as the sector number and the track number.
- Data Area: The portion where actual user data is stored.
- Trailer: Contains error-correcting codes (ECC) to ensure data integrity and facilitate error detection and correction.
- Importance: Low-level formatting is essential for the disk to be recognized and used by the operating system. It lays the groundwork for organizing the data that will be stored.
b. Logical Formatting (File System Creation)
- After low-level formatting, logical formatting organizes the disk into logical structures recognized by the operating system.
- Process:
- Partitioning: The disk is divided into partitions, which are treated as separate logical disks. Each partition can have its file system.
- File System Creation: The operating system sets up file system data structures (e.g., File Allocation Table (FAT), inode tables) on the disk, defining how data will be stored, accessed, and managed.
- Importance: Logical formatting is crucial for managing files and directories on the disk. It provides a framework for the organization of data and enables efficient file access.
2. Boot Block
The boot block is a special area on the disk that contains essential code for system initialization upon startup.
Responsibilities of the Boot Block
- Bootstrap Program: The boot block contains a bootstrap program that initializes the system.
- Initialization Tasks:
- CPU and Device Initialization: It initializes CPU registers, device controllers, and main memory to prepare the system for operation.
- Locating and Loading the OS: The bootstrap program locates the operating system kernel stored on the disk, loads it into memory, and transfers control to it so that the operating system can start managing hardware resources.
Storage of the Bootstrap Program
- ROM Storage: The bootstrap program is often stored in read-only memory (ROM) to protect it from corruption, such as from viruses. This ensures that the initial instructions needed to start the system remain intact.
- Hardware Changes for Updates: Updating the bootstrap code generally requires physical changes to the hardware, which is impractical.
- Tiny Bootstrap Loader: To provide flexibility, a small bootstrap loader may be stored in ROM. This loader can load a more comprehensive bootstrap program from the disk, which can be updated as necessary.
3. Bad Blocks
Bad blocks are areas on a disk that have become unusable due to wear and tear, manufacturing defects, or other reasons. They can be a significant issue in maintaining data integrity and availability.
Handling Bad Blocks
- Initialization During Low-Level Formatting: During low-level formatting, the system creates an initial list of bad blocks to track which sectors are defective and should be avoided during read/write operations.
- Sector Sparing:
- Definition: Sector sparing is a technique used to manage bad blocks by replacing them with spare sectors.
- Detection and Replacement: When a bad sector is detected, the disk controller logically replaces it with a designated spare sector. This minimizes the impact of the defective sector on overall performance and maintains data integrity.
Example of Bad Block Management
- Sparing Process: If a sector is identified as bad, the disk might use a reserved spare sector located elsewhere on the disk to replace it. The logical mapping of the data would update so that requests for the bad sector would be redirected to the spare.
- Importance: Handling bad blocks is essential to ensure data remains accessible and to prolong the lifespan of the disk. Without such management, user data could be lost, and system reliability could be compromised.





